데이터 모델 D
- S, O, C
- Structure(구조), Operation(연산), Constraint(제약조건)
- ex) 정수(Integer)
구조 : ..., -2 -1 0 1 2, ...
연산 : 사칙연산(+,-,x,/)
제약조건 ↓

구조
- 데이터의 정적인 성질
- 개체 타입과 이들 간의 관계를 표현
연산
- 데이터의 동적인 성질
- 개체를 처리하는 작업에 대한 명세, 데이터 조작 기법
제약조건
- 데이터의 논리적 제약
- 데이터 조작의 한계를 표현한 규정
데이터베이스의 구성 요소
1. 개념적 구조
- 사용자 입장에서의 구성 요소
- ex) 데이터베이스 = {개체,관계}
- 개체 (Entyty)
- 표현하고자 하는 현실 세계에 존재하는 유/무형의 객체
- 반드시 물질적으로 존재할 필요는 없음. -> ex) 수강신청, 계약
- 데이터베이스에 표현되는 정보의 단위
- 개체는 하나 이상의 속성(Attribute)로 구성
- 파일 시스템의 레코드(Record)에 대응되는 개념
- 개체 집합(Entity Set) <-> 개체 인스턴스(Entity Instance) - ** 속성 : 데이터의 가장 작은 논리적인 단위 / 물리적인 단위 : Bit
- 개체 타입(Entity Type)
- 개체 집합에 속한 개체 인스턴스들이 공통으로 가지는 특징(구조) - 관계(Reationship)
- 개체들 사이에 존재하는 연관성
- ex) 교수와 학생 사이에는 지도 관계 / 신랑과 신부 사이에는 결혼 관계
2. 논리적 구조
- 컴퓨터가 처리할 수 있는 데이터 모델!
- 컴퓨터가 인식하고 처리할 수 있는 데이터의 논리적 구조
- 데이터베이스 관리 시스템과 사용자가 공통으로 인식하는 구조
- -> 데이터의 논리적 배치와 구성을 나타냄
- 데이터베이스는 주로 관계형 데이터 모델에 기반함
- 최근 데이터베이스 관리 시스템들은 "객체 관계형 모델"을 사용


3. 물리적 구조
- 저장 미디어에서 본 데이터의 물리적 배치 및 구성
- 하드 디스크, SSD, DVD와 같은 저장 미디어에서 본 데이터의 물리적인 배치 및 구성
- 컴퓨터 위주의 표현 방식으로 저장 장치에 저장된 데이터의 "실제 구조 및 접근 방법"
- 일반 사용자나 응용 프로그래머들은 물리적 구조를 "인지하거나 파악하지 못함"
※ 데이터베이스 구성 시 유의사항
- 데이터베이스의 논리적 구조는 "사용자가 숙지"하고 있어야 함
- 물리적 구조는 일반 사용자가 숙지할 필요는 없음
- 논리적 구조와 물리적 구조 사이의 "도표화(Mapping)는 데이터베이스 관리 시스템이 지원함"
- 데이터 종속성의 해결 -> 데이터 독립성
관계형 데이터 모델
- Relational Data Model
- 데이터베이스에서 "가장 많이" 쓰이고 있는 논리적 모델
- 단순한 모델 구조
- 수학적 이론(집합론(Set Theory))에 기반한 모델의 강건(Sound)함
- SQL이라는 간단한 비절차적 언어로 쉬운 데이터 처리 가능!
집합론
- 창시자 : 독일 수학자 칸토어
- 우리의 직관 또는 사고의 대상 중에서 "확정"되어 있고 "서로 명확히 구별" 되는 것들의 모임
- 구체적/객관적 기준에 의해 원소를 명확히 구분 가능해야 함.
-> 집합을 구성하는 원소 : 집합 내에서 유일하게 식별 될 수 있어야 함. - 논리적인 개념도 집합의 구성 요소가 될 수 잇음.
-> 눈으로 보거나 손으로 만질 수 없더라도 첫 번째 조건을 충족하는 개념이라면 이 역시 집합이 될 수 있음!
집합
- 군집(Colleciton)
- "동일한 유형"의 원소들이 모여 있는 군집 (=타입이 같다)
- 하위 타입 : Set, Bag, List, Array - Set (집합)
- 원소의 "중복 불가"
- 원소들 간의 순서 없음
ex) {1,2,3} = {3,1,2} ≠ {1,2,2,3} - Bag (또는 Multi-Set)
- 원소의 "중복 허용"
- 원소들 간의 순서 없음
ex) {1,2,2,3} = {3,1,2,2} - list
- 원소의 중복 불가
- 원소들 간의 "순서 있음"
ex) {1,2,3} ≠ {3,1,2} - Array
- 원소의 중복 허용
- 원소들 간의 "순서 있음"

관계형 데이터 모델의 구성요소
- 구조
- 릴레이션(또는 테이블) - 연산
- 관계 대수(Relational Algebra)
- 관계 해석(Relational Calculus) - 제약조건
- 무결성(Integrity) 제약조건
릴레이션
1. 관계형 데이터 모델의 구조(Structure)
- 2차원 테이블 구조
- 테이블의 행(Row) : 튜플(Tuple)
- 릴레이션은 튜플들의 집합 (-> 중복x , 순서x)
- 개념적 모델의 개체(Entity)가 관계형 모델에서 한 튜플에 대응됨
- 개념적 모델의 관계(Relationship)도 관계형 모델에서 한 튜플에 대응됨
- 테이블의 열(Column) : 속성(Attribute)
- 도메인 (Domain) = 한 속성이 가질 수 있는 값의 범위!

2. 속성(Attribute)
- 관계형 데이터 모델에서 데이터의 가장 작은 논리적 단위
- 관계형 모델에서는 이 데이터 값들을 더 분해하려고 해도 더 분해할 수 없는 원자 값(Atomic Value)만을 허용
- -> 원자 값은 아무런 내부적 구조를 지니고 있지 않음!
3. 도메인(Domain)
- 하나의 속성이 취할 수 있는 값들의 집합
- 도메인과 속성의 관계는 프로그래밍 언어에서 "타입과 변수에 비유"
- 어떤 데이터 타입으로 선언된 변수는 언제 어느 때고 그 선언된 데이터 타입의 값만을 가짐!
ex) int x -> 변수 x는 정수형 값만을 가진다. - 속성 정의시 도메인도 함께 명세함으로써 실제 속성이 지니는 값이 합법적인지 아닌지를 데이터베이스 관리 시스템(DBMS)을 통해 검사 가능!
- 어떤 릴레이션 R이 n개(=속성이 n개)의 도메인 D1, D2, ..., Dn으로 구성될 때

4. 수학적 정의

- X : 카티션 프로덕트(Cartesian Product)
- 집합론에서 사용되는 곱셈 연산
- 두 집합에 속한 원소들을 이용하여 모든 가능한 쌍 만들기

- t ∈R : t를 릴레이션 R에 속한 한 튜플이라고 가정한 경우

5. 릴레이션의 특성
- 튜플의 유일성
- 릴레이션은 튜플의 집합
- 집합은 "중복을 허용하지 않음" - 튜플의 무순서성
- 릴레이션은 튜플의 집합
- 집합에서 "원소들 간의 순서는 없음" - 속성의 무순서성
- 스키마는 속성들의 집합 - 속성의 원자성(Atomicity)
- 속성 값은 원자 값
- **원자(Atom) : 더 이상 쪼갤 수 없는 "물질의 최소 단위"
- 속성은 개체를 구성하는 가장 작은 논리적 단위
- **논리적으로 더 분해할 수 없음
- 한 릴레이션에 나타난 속성값은 논리적으로 더 이상 분해될 수 없는 원자값!
- **처리상의 단위 값 : Unit Value
- 이 성질의 근본적인 의미 : 튜플의 속성값은 하나의 값만을 허용 ★
- ** 반복 그룹, 즉 값의 집합은 허용하지 않음
- ** 반복 그룹을 허용하지 않는 릴레이션 : 정규화 릴레이션(Normalized Relation)
- 관계형 데이터 모델은 이 정규화 릴레이션만을 취급합!

1. 속성 (Attribute)
학번, 이름, 학과명, 성별, 성적
2. 도메인
성별 속성의 도메인은 남, 녀
3. 차수
학번, 이름, 학과명, 성별, 성적 = 총 5개
4. 튜플
첫번째 행의 20051201 김철수 컴퓨터 남 85 = 하나의 튜플
5. 카디널리티
튜플의수 = 5개
6. 릴레이션
테이블 = 중복된 튜플 x / 중복된 속성 x
관계 대수와 관계 해석
- 릴레이션을 조작하기 위한 연산
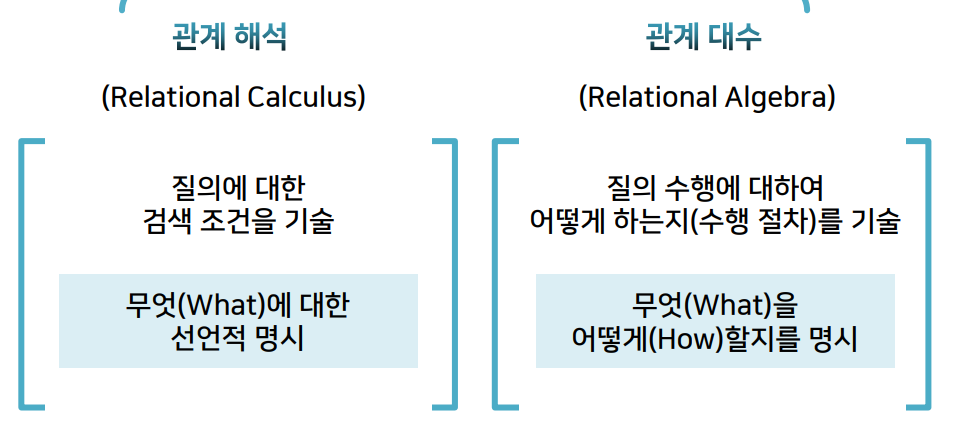
관계 해석
- Relational Calculus
- 관계 대수로 명시할 수 있는 모든 검색 요구는 관계 해석으로도 명시할 수 있으며, 그 역도 성립됨이 증명됨
- --> 두 언어의 표현력(Expression Power)은 동등
- 관계형 데이터베이스의 표준 질의 언어 : SQL
- --> 관계 해석(튜플 관계 해석)을 기반으로 만들어짐.
- --> 무엇(What)만을 기술
- 관계형 데이터베이스 내에서 SQL을 처리하는 방법
- --> 관계 대수를 기반으로 함
--> 어떤 순서로 처리하는지가 중요해 짐 --> 질의 최적화 - 관계 해석의 기반 : 수학의 술어해석(Predicate Calculus)
- 관계 해석의 제안 : 데이터베이스 언어의 기초로 사용되기 위해 코드(E.F. Codd)박사에 의하여 제안

튜플 관계 해석
- 튜플 변수(Tuple Variable)를 명시
- 튜플 변수의 범위 : 릴레이션
-> 튜플 변수는 주어진 릴레이션의 어떤 튜플도 값으로 가질 수 있음! - 형태

ex) 성적이 3.5 이상인 학생을 구하는 튜플 해석식

- 튜플 관계 해석식에서 명시해야 하는 것
1. 각 튜플 변수 t의 범위 릴레이션
2. 튜플들을 특정 조합들로 선택하기 위한 조건
3. 검색 속성들의 집합
- 일반적인 튜플 관계 해석식

WFF
- 원자(Atom)들로 구성된 식
- 원자(Atom)
- R(t)형태 : 튜플 변수와 대응되는 범위 릴레이션

- 원자는 WFF
- F(어떠한 식)가 WFF이면 (F)와 ¬(not을 뜻함)F도 WFF
- F와 G가 WFF이면 F and G와 F or G도 WFF
- F(t)가 WFF이면 ∀t(F(t))와 ∃t(F(t))도 WFF


튜플 관계 해석 예시
예시 1 : 학번이 100번인 학생의 이름, 주소를 검색하시오

- 해당 질의에 대한 튜플 해석식이 오직 하나만 있는 것은 아님
- 같은 결과를 얻을 수 있는 많은 식이 있음.
ex) 1+1 = 1-1+2 = 1/1+1 = ....

예시 2 : 컴퓨터공학과에 속한 모든 학생의 이름과 학번을 구하시오.
- 해당 질의에 학생 릴레이션은 학과번호를 속성으로 가짐
- 학과 릴레이션에 학과명과 학과번호가 있음.

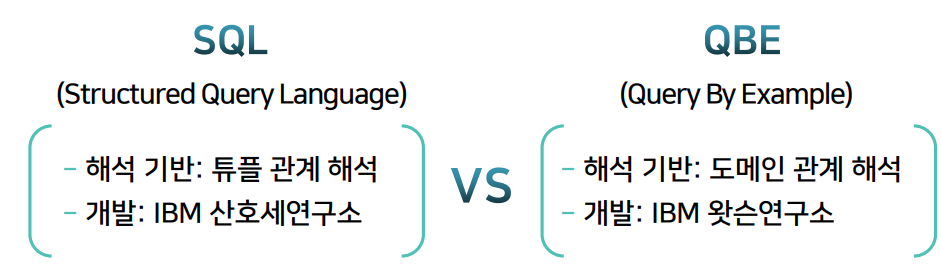
도메인 관계 해석
- 튜플 관계 해석을 기반으로 한 언어인 SQL은 IBM 산호세연구소에서 개발
- 도메인 관계 해석을 기반으로 한 QBE가 IBM 왓슨연구소에서 개발
- 도메인 해석과 튜플 해석은 "사용되는 변수의 유형만 다를 뿐" 유사함
- 도메인 해석에서 변수의 범위는 튜플이 아니라 "속성의 도메인에 속한 값"
==> 질의 결과로 차수가 n인 릴레이션을 생성하기 위해서는, 각 속성 마다 하나씩 총 n개의 도메인 변수(Domain Variable)이 필요함.
- 도메인 해석과 튜플 해석 : 사용되는 변수의 유형만 다를 뿐 유사함
- 도메인 해석에서 변수의 범위 : 속성의 도메인에 속한 값
==> 질의 결과로 차수가 n인 릴레이션을 생성하기 위해서는 각 속성 마다 하나씩 총 n개의 도메인 변수가 필요함!
도메인 관계 해석식

- 원자식이 필요함

WFF(Well Formed Formula)
- 원자는 WFF
- F가 WFF이면 (F)와 ¬F도 WFF
- F와 G가 WFF이면 F and G와 F or G도 WFF
- F(x)가 WFF이면 ∀x(F(x))와 ∃x(F(x))도 WFF
ex) 컴퓨터공학과에 속한 모든 학생의이름과 학번을 구하시오.
- 학생 릴레이션은 학과번호를 속성으로 가짐
- 학과 릴레이션에 학과명과 학과번호가 있음

QBE
- Query By Example
- 2차원 그래픽 터미널 이용
- MS-ACCESS에서 QBE를 지원
- Microsoft 사에서 제공되는 데이터베이스 관리용 애플리케이션
- 간단하고 편리한 기능 제공
- 초보 사용자가 데이터베이스를 구축, 관리에 용이함

MS-ACCESS의 쿼리 디자인 기능

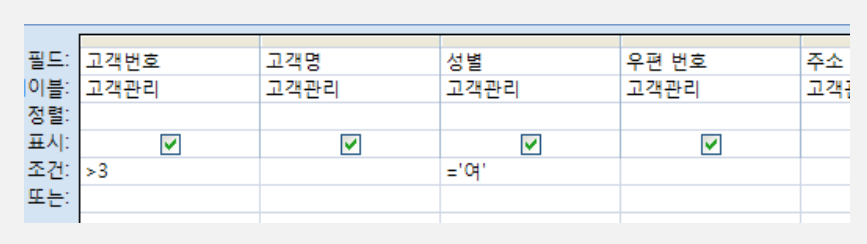
- 고객관리 테이블에서 성별이 "남"인 고객의 정보를 검색


- 고객관리 테이블에서 성별이 "여"이고 고객번호가 3보다 큰 고객 정보를 검색
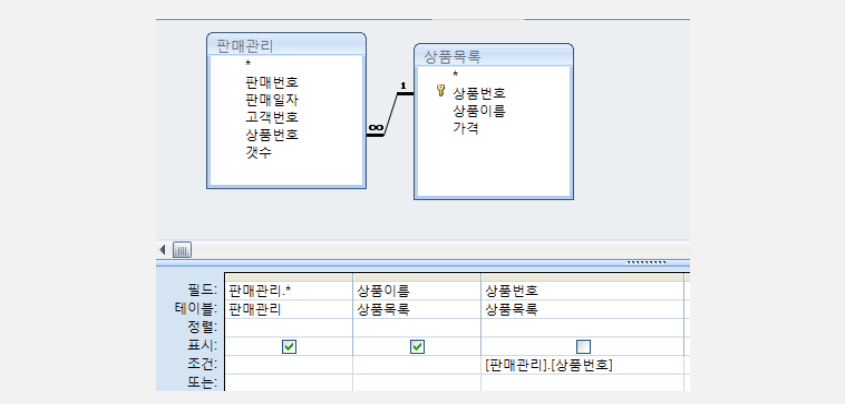
다중 테이블 검색
- 상품목록 테이블과 판매관리 테이블을 이용하여 각 판매정보에 상품명을 표시

관계 대수
- Relational Algebra
- 관계 해석은 "질의"를 나타내기 위한 "선언적 표기법"
- 관계형 모델에서의 "기본적인 연산들의 집합"
- 관계 대수의 중요성
1. 관계형 모델의 연산을 위한 공식적인 토대를 제공
2. DBMS에서 질의를 구현하고 최적화 하기 위한 기반
3. 관계 대수의 몇 가지 개념은 SQL 표준 질의에 반영됨
관계형 모델에 기반한 분류 / 피연산자의 수에 따른 분류


단항 연산자
- 셀렉트 연산
- 릴레이션에 선택 조건을 기술하여 "조건을 만족하는 튜플들을 선택"하는데 사용하는 연산 - 프로젝트 연산
- 릴레이션에서 "특정 속성들만을 선택"하는 연산
이항 연산자
- 합집합, 교집합, 차집합, 카티션 곱
- 릴레이션은 튜플들의 집합
- 따라서 "집합 연산자를 사용 가능" - 조인
- 두 릴레이션으로부터 "관련된 튜플들을 결합"하여 하나의 튜플로 만듦
폐쇄 성질 (Closure Property)
- 피연산자와 연산자의 결과가 같은 자료형
- 피연산자(Operand) = 연산에 참여하는 자료
- 연산자(Operator) = 자료를 처리하는 방법
- 모든 연산자가 폐쇄 성질을 가지는 것은 아님!

폐쇄 성질의 특징
- 관계 대수의 모든 연산은 릴레이션에 대하여 폐쇄 성질을 지님
- 어떤 릴레이션에 관계 대수 연산을 수행하면 그 결과도 릴레이션(튜플의 집합) 임 - 관계 대수는 "질의 처리의 대상(What)과 절차(How)를 나타냄!
- 폐쇄 성질이 없으면 절차를 자유스럽게 표현하기 어려움 - 폐쇄 성질에 따라서 "연산자의 중첩(Nesting) 순서" 를 표현
- 연산자 3(연산자2(연산자1(릴레이션))) -->> 릴레이션
셀렉트
- 릴레이션에 선택 조건을 기술하면 조건을 만족하는 튜플들을 선택하는데 사용
조인
- 두 릴레이션으로부터 관련된 튜플들을 결합하여 하나의 튜플들로 만듦
'기초 물방울 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 기초 개념, 관리 시스템(수업) #1 (0) | 2022.07.11 |
|---|